DALL-E-3 prompt for the header image: “cartoon image of a scientist doing experiments in lab. There should be beakers containing mixtures of different letters, and the scientist is pouring one of those beakers into a robot who is holding a pen (this robot represents a LLM, and the beakers represent different prompts the scientist is testing in order to get the LLM to generate the results they want)”
tl;dr
– Testing different prompts can improve your outputs significantly.
– Even small formatting changes can make a big difference in prompt performance.
– You need to test prompts across different models and over time, as models behave differently from each other and can change over time.
If you’re using AI for content creation at scale, you (or someone on your team) should be spending a fair amount of time testing different prompts.
It’s easy to overlook this part of the process, especially as large language models (LLMs) like GPT-4 improve. If you were using GPT-3 in 2022 before the release of ChatGPT, for example, the need for testing was painfully obvious: A poorly formatted prompt would often get you gibberish.With today’s LLMs, though, you’ll likely get a decent enough output from the first prompt you try, making it easy to assume there aren’t many gains to be made.
Even as the floor of LLM performance has been raised, though (ie. fewer responses that are complete gibberish), the ceiling has also been raised. You’ll leave a lot of capabilities on the table if you aren’t regularly testing to optimize your prompts.
If you’re using AI at scale to run prompts over 100s or 1000s of inputs, this testing becomes even more important. Even if better prompts only provide marginally better results on a single input, those improvements add up quickly when you’re using those prompts at scale.
In this article, I’m going to walk through recent research and AI happenings to explain three aspects of LLMs and prompting that make testing so important. In the next article, I’ll share my own most recent experiments for our human-crafted AI content offering to show what I tested, how I set it up, and what my results were.
But first: What do I mean by using AI at scale?
When I talk about using AI at scale to create content, I’m talking about using large language models through an API, where you’re using the same prompt template over and over again on different inputs.
For example, you might have a prompt you use to generate an outline for an article. The basic prompt structure could look something like this:
Write an outline for this article.
topic: {topic}
word count: {word_count}
primary keyword: {keyword}
You’d then run this prompt on a list of briefs, automatically filling in each of the bracketed variables with the appropriate information for each article. You might then write the output of each prompt to a new Google Doc, or store the outline alongside the article information in whatever project management tool you use.
There are unlimited ways to set up a workflow to use AI programmatically like this, depending on what your current content creation tech stack looks like. For many workflows, you may want to use a tool like Zapier or Make as a no-code option. I’ll go into more of the technical stuff in other posts, but it’s important to understand that I’m not talking about you as an individual user working directly in ChatGPT or another LLM-enabled tool here.
Three reasons you need to test different prompts for AI content creation
If you’re only using ChatGPT for one-off tasks, it’s still worth testing different prompts if for no other reason than you might learn surprising things about how it behaves. When you’re using prompts at scale and running them on dozens of inputs at a time, though—which is where you really start to see the efficiency gains from AI—testing becomes a non-negotiable.
Here are three of the biggest reasons why:
1. Prompt details matter—even ones you think shouldn’t
Even tiny changes in a prompt can make a big difference.
A team from the University of Washington recently published a paper with the great subtitle of “How I learned to start worrying about prompt formatting.” If you don’t read academic papers for fun, this Twitter thread from lead researcher Melanie Sclar does a great job summarizing the findings.
The key takeaway, though, is this image:
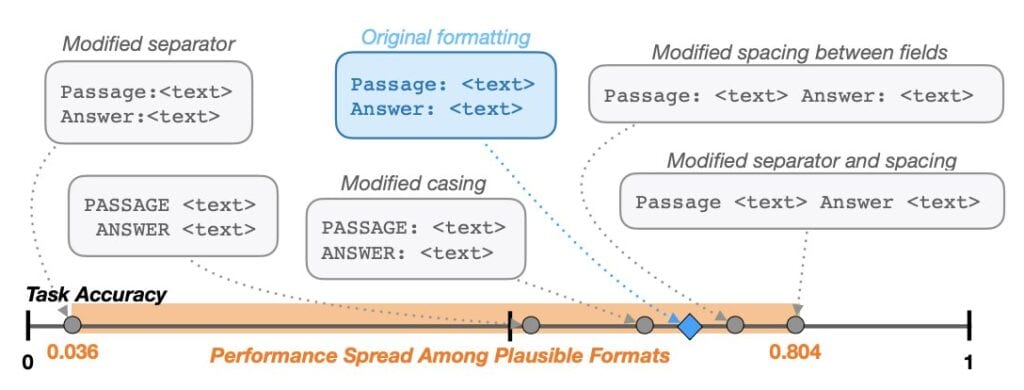
This is WILD.
Here’s what it’s showing: The blue box shows the default formatting of their prompt. The small blue diamond shows how accurate the model’s output was when that prompt was used—roughly midway between 0.5 and 0.804 on the scale.
The other boxes show different ways of formatting that same prompt. In the top left box, for example, the space has been removed between “Passage:” and “<text>,” and “Answer:” and “<text>.” In the top right box, the passage and answer are both on the same line. In the bottom right, they’re on the same line and the colon has been removed. In the bottom middle, “Passage” and “Answer” have been written in all caps. In the bottom left, they’re in all caps and the colon has been removed. In each case, the dotted line shows where the accuracy of the model’s response to that prompt fell on the scale.
The important thing to note is that none of those changes impact the content of the prompt. A human reader would interpret these formats as all saying the same thing, and the model is still getting the exact same examples to help it understand what it’s supposed to do. The only things that are different are the spacing, capitalization, and punctuation. And yet, those arbitrary formatting choices impact the accuracy of its output tremendously, ranging from 3.6 percent accuracy when the space was removed in the top left box, to 80.4 percent accuracy when the passage and answer were on the same line with no colon, as shown in the bottom right box.
The takeaway here is to test variations of your prompt, even if it’s only changing small things you think shouldn’t make a difference. LLMs might be predictive, but their behavior is often far from predictable.
2. Every LLM is a special snowflake ❄️
One other important takeaway from that paper: You won’t be able to find the best format for your prompt and simply use it forever on any model you want. From Appendix B.2:
“Table 3 shows that if format p1 has lower performance than format p2 under model M, there is < 0.62 probability that this trend would hold under another model M′ (random chance is 0.5). This weak relative order preservation suggests that prompt format performance in a model may not be extrapolated to a different model, or in other words, that there are no inherently good or bad formats.“ (emphasis mine)
The corollary of the finding that there are no inherently good or bad formats is that every model behaves differently. Just like all humans are different, AI is not a single, monolithic entity that always behaves the same way. Each model has its own quirks and will respond to prompts in different ways.
When a new state-of-the-art model is released, it likely will be “better” than its predecessors, in the sense that it will be more capable of producing useful responses. However, it will also be simply different than whatever model you were previously using, so you can’t keep using the same prompts and expect to get the same or better results.
Anytime a new model comes out, or if you switch models for any reason, you need to test your prompts on that model.
If, for example, you wanted to switch over to Anthropic’s models during the OpenAI drama with Sam Altman last November, you would have quickly learned that the prompts you use with GPT-4 don’t work the same way with Claude-2. One immediately obvious difference is that Claude-2 is much more likely to preface its responses with friendly fluff like “Sure! Here’s the xyz you asked for… ,” or say things like “I apologize, upon reflection I do not feel comfortable providing advice to befriend or interact with Sasquatch (Bigfoot), as that could encourage harmful behavior. Instead, I suggest focusing content on appreciating nature, caring for the environment, and respecting wildlife from a safe distance” when asked to write an outline for a satirical article on how to befriend Sasquatch. (That’s a purely hypothetical example, of course.)

There are other, more significant differences between the two models, though, which mean you should expect to use different prompting strategies with each one.
Bonus: Check out the Chatbot Arena Leaderboard to see LLMs engaged in gladiator-style combat which LLMs are currently ranked the best, both by crowdsourced voting and by their performance on certain benchmarks.
3. Model behaviors can (and do) change over time
So, you should both test your prompts initially to find the most effective ones as well as re-test them anytime you’re changing models. That’s not all, though: You also need to re-test them periodically, even if you’re still using the same model.
Why? Because models are constantly being updated behind-the-scenes, and this can change their behavior.
In 2023, for example, there was a lot of talk around GPT-4’s performance degrading, with users saying it had gotten “lazier.”
Earlier that year, researchers at Stanford and Berkeley published a paper showing how the performance of GPT-3.5 and GPT-4 had changed significantly over time. While it’s not correct to say that the models had gotten strictly worse, it is definitely true that their performance had changed. If you’re using prompts in your content workflow—or if you’ve built a product atop LLMs—and the model’s behavior changes, whether for better or worse, you need to know that.
To better understand the results of that paper, check out this article for a great analysis of the findings and methods. It also gives a useful explanation of why model behavior changes (a phenomenon called “behavior drift”) and how that’s different than their actual capabilities changing, even though it may look similar to users:
“Behavior drift makes it hard to build reliable products on top of LLM APIs. The user impact of behavior change and capability degradation can be very similar. Users tend to have specific workflows and prompting strategies that work well for their use cases. Given the nondeterministic nature of LLMs, it takes a lot of work to discover these strategies and arrive at a workflow that is well suited for a particular application. So when there is a behavior drift, those workflows might stop working.”
– Arvind Narayanan and Sayash Kapoor, authors of AI Snake Oil
In other words? A prompt that gave you a great article outline yesterday might work very differently today. There could be subtle changes over time or a more dramatic shift, but either way: Continuous testing is essential.
These reasons are why I spend a significant amount of my time testing different prompts to use with the AI tools we’ve built for our writers. It’s important to keep in mind that even as the baseline of AI performance goes up, you can still get even better results by spending a bit of time playing around with different prompts and strategies.
Comments? Questions? Vehement disagreements? Reach me at megan@verblio.com, and check out my next article to learn my process for testing 55 different prompts for our own AI-assisted content.


